Abstract
For talking head generation and its downstream applications, the generalized audio-driven lip-sync technology is of great significance. However, existing methods still face challenges in eliminating artifacts in the generated frames and maintaining the personalized speaking style of the template video. In this paper, we propose StyleGeoSync, a generalized high-fidelity lip-sync framework, consisting of style-aware audio-driven spatial geometry construction and 3D facial segmentation-guided texture generation. To achieve personalized and style-consistent lip synchronization, we introduce a style condition mechanism that disentangles lip motion into audio-related absolute dynamics and audio-independent speaking style. Moreover, to fundamentally eliminate visual artifacts, we design the texture generation as a standalone module, which prevents interference from the reference image during lip motion synthesis. By decoupling lip movements and image textures into two stages, this framework can generate lip-synced videos with better image quality according to the given audio, and achieve specific speaking style transfer based on the reference video. Experimental results on CelebV-HQ and HDTF datasets demonstrate that our proposed method outperforms existing methods in image quality, lip synchronization, and identity preservation.
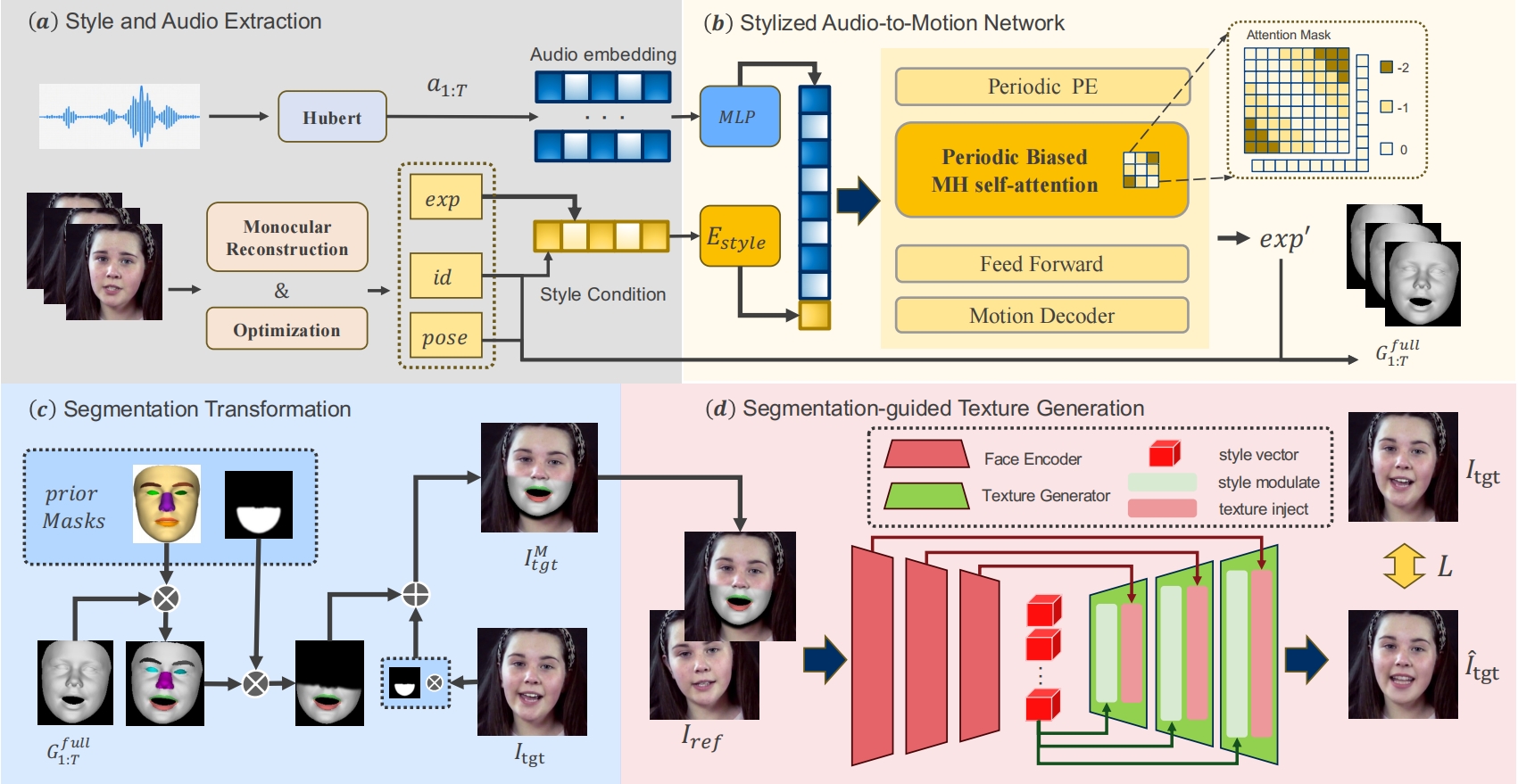
The overall framework of StyleGeoSync. Firstly, the (a) Style and Audio Extraction module is used to obtain the speaking style and audio embedding of the reference video. Then, the (b) Stylized Audio-to-Motion Network predicts the stylized expression coefficients, which are subsequently employed to construct the spatial facial geometry. Next, the (c) Segmentation Transformation module leverages prior Mesh-Part-Masks to transform the geometry into 3D face segmentation maps. Finally, after the (d) Segmentation-guided Texture Generation process, the target video is generated.